Unexpected Termination of Spot Instances in AutoScaling Group
Analysis of the causes and countermeasures for unexpected spot instance termination in AWS AutoScaling Group.
Introduction
A spot instance running in an AWS AutoScaling Group was unexpectedly terminated. This was a termination for reasons other than forced reclamation, and I analyzed the cause, impact, and countermeasures.
Problem Situation
1. Symptoms
- A spot instance consuming message queues was terminated even though it wasn’t forcibly reclaimed
- Received notification that a new instance was started
- Fortunately, another server processed the
requeuedmessages, so there was no service interruption
AutoScaling Group Log
1
2
3
4
5
6
At 2023-07-09T00:32:21Z instances were launched to balance instances
in zones null with other zones resulting in more than desired number
of instances in the group.
At 2023-07-09T00:46:17Z availability zones
had 4 1 instances respectively. An instance was launched to aid in
balancing the group's zones.
Looking at the details more closely:
1
2
3
4
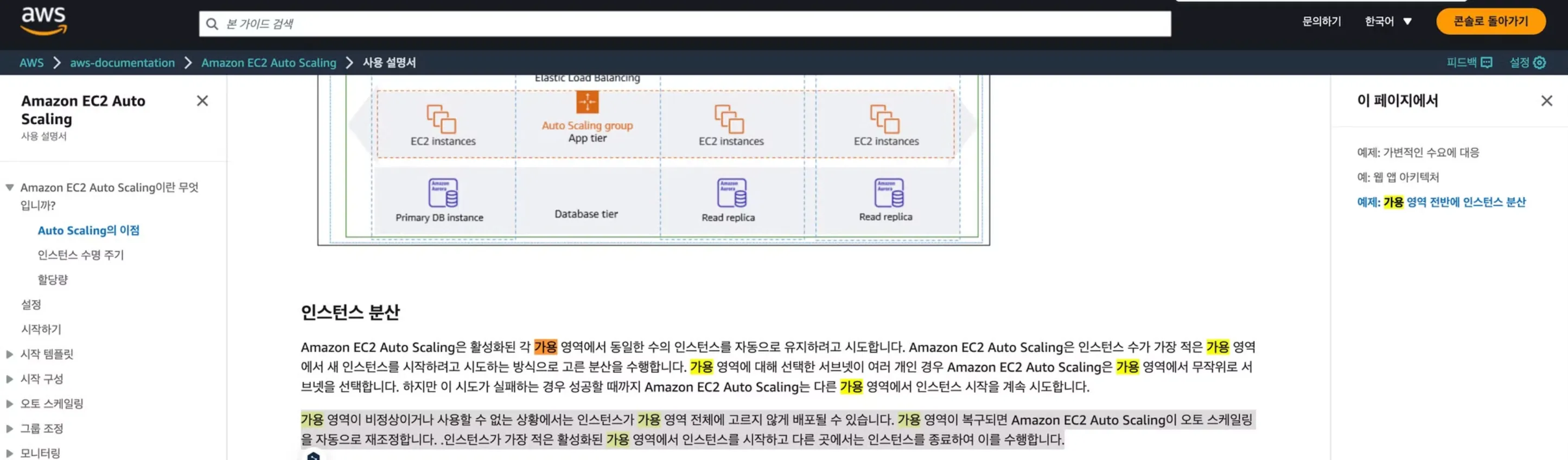
Availability zones are isolated locations within a region. These are independent zones, for example us-west-2a, us-west-2b, us-west-2c.
AutoScaling distributes instances evenly across each availability zone.
At this time, it launches instances in the availability zone with the fewest active instances and terminates instances elsewhere to achieve this.
Conclusion
- In other words, the problem occurred because an instance in a region with many instances was terminated to evenly distribute the number of instances across each region
- Fortunately, it’s very rare for an instance processing user requests to die, and most of the time it’s a newly launched instance that gets terminated. Even if an instance processing requests dies, unprocessed messages are
requeuedback into the queue, so we resolved it by just logging to Slack
This post is licensed under CC BY 4.0 by the author.